43 variational autoencoder for deep learning of images labels and captions
List of datasets for machine-learning research - Wikipedia Images plus .mat file labels Human pose estimation 2011 S. Johnson and M. Everingham MCQ Dataset 6 different real multiple choice-based exams (735 answer sheets and 33,540 answer boxes) to evaluate computer vision techniques and systems developed for multiple choice test assessment systems. None 735 answer sheets and 33,540 answer boxes Images ... GitHub - DirtyHarryLYL/Transformer-in-Vision: Recent ... (arXiv 2022.07) A Variational AutoEncoder for Transformers with Nonparametric Variational Information Bottleneck, (arXiv 2022.07) Online Continual Learning with Contrastive Vision Transformer, (arXiv 2022.07) Retrieval-Augmented Transformer for Image Captioning,
Image classification | TensorFlow Core Aug 12, 2022 · This is a batch of 32 images of shape 180x180x3 (the last dimension refers to color channels RGB). The label_batch is a tensor of the shape (32,), these are corresponding labels to the 32 images. You can call .numpy() on the image_batch and labels_batch tensors to convert them to a numpy.ndarray. Configure the dataset for performance

Variational autoencoder for deep learning of images labels and captions
A Survey on Deep Learning for Multimodal Data Fusion May 01, 2020 · Abstract. With the wide deployments of heterogeneous networks, huge amounts of data with characteristics of high volume, high variety, high velocity, and high veracity are generated. These data, referred to multimodal big data, contain abundant intermodality and cross-modality information and pose vast challenges on traditional data fusion methods. In this review, we present some pioneering ... 2019 IEEE/CVF Conference on Computer Vision and Pattern ... Jun 15, 2019 · A Skeleton-Bridged Deep Learning Approach for Generating Meshes of Complex Topologies From Single RGB Images pp. 4536-4545 Learning Structure-And-Motion-Aware Rolling Shutter Correction pp. 4546-4555 PVNet: Pixel-Wise Voting Network for 6DoF Pose Estimation pp. 4556-4565 DeepTCR is a deep learning framework for revealing sequence ... Mar 11, 2021 · A variational autoencoder provides superior antigen-specific clustering ... Y. et al. Variational autoencoder for deep learning of images, labels and captions. Adv. Neural Inf. Process. Syst. 29 ...
Variational autoencoder for deep learning of images labels and captions. robmarkcole/satellite-image-deep-learning - GitHub deeppop-> Deep Learning Approach for Population Estimation from Satellite Imagery, also on Github; Estimating telecoms demand in areas of poor data availability-> with papers on arxiv and Science Direct; satimage-> Code and models for the manuscript "Predicting Poverty and Developmental Statistics from Satellite Images using Multi-task Deep ... DeepTCR is a deep learning framework for revealing sequence ... Mar 11, 2021 · A variational autoencoder provides superior antigen-specific clustering ... Y. et al. Variational autoencoder for deep learning of images, labels and captions. Adv. Neural Inf. Process. Syst. 29 ... 2019 IEEE/CVF Conference on Computer Vision and Pattern ... Jun 15, 2019 · A Skeleton-Bridged Deep Learning Approach for Generating Meshes of Complex Topologies From Single RGB Images pp. 4536-4545 Learning Structure-And-Motion-Aware Rolling Shutter Correction pp. 4546-4555 PVNet: Pixel-Wise Voting Network for 6DoF Pose Estimation pp. 4556-4565 A Survey on Deep Learning for Multimodal Data Fusion May 01, 2020 · Abstract. With the wide deployments of heterogeneous networks, huge amounts of data with characteristics of high volume, high variety, high velocity, and high veracity are generated. These data, referred to multimodal big data, contain abundant intermodality and cross-modality information and pose vast challenges on traditional data fusion methods. In this review, we present some pioneering ...
How to Generate Images using Autoencoders | AI Summer

VAE: giving your Autoencoder the power of imagination
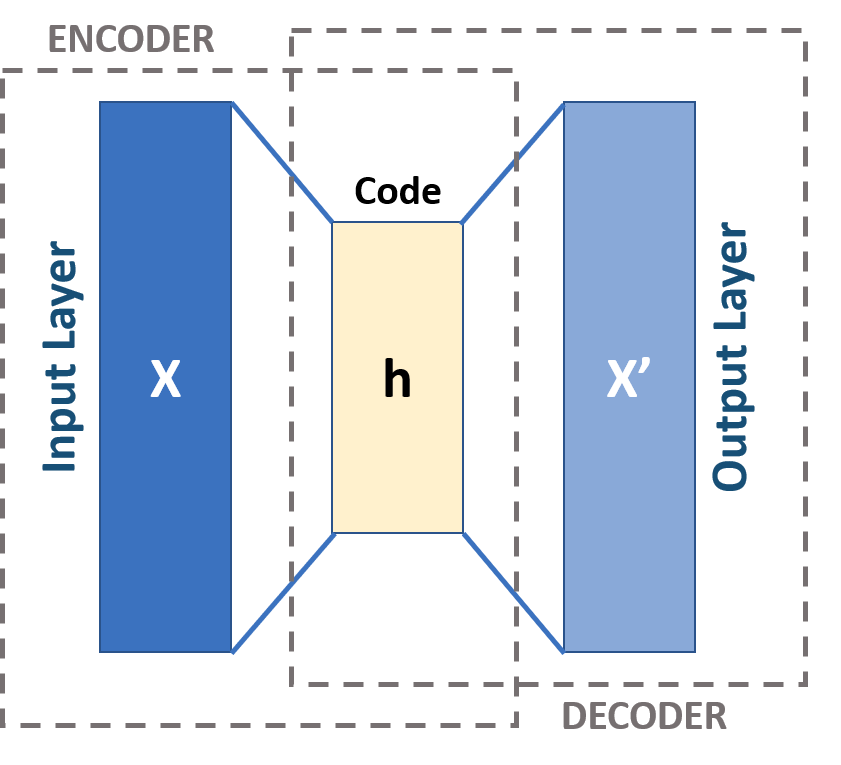
Autoencoder: Deep Learning Swiss Army Knife - Fingerprints
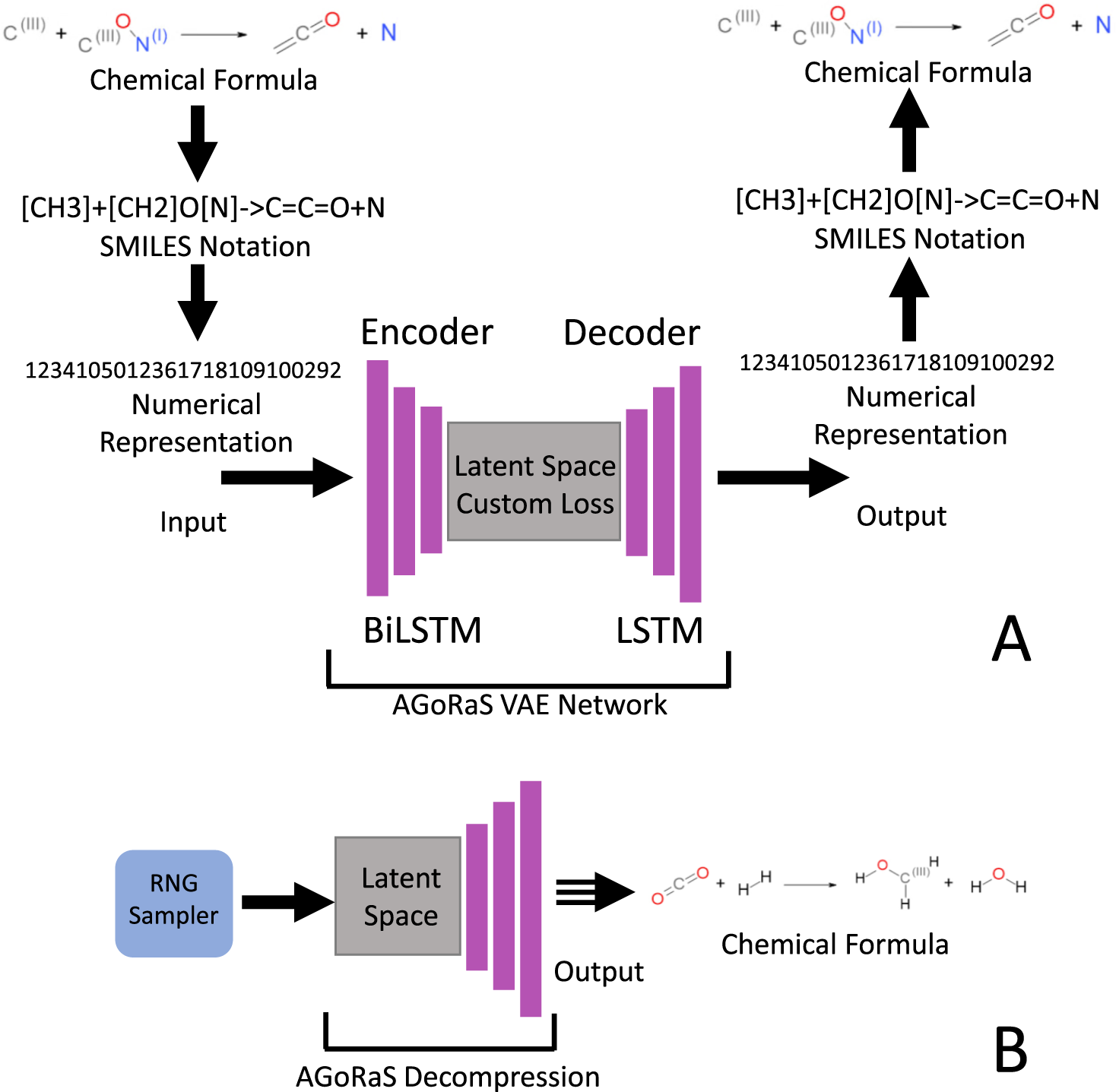
Autonomous design of new chemical reactions using a ...
![Autoencoders in Deep Learning: Tutorial & Use Cases [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/627d121bd4fd200d73814c11_60bcd0b7b750bae1a953d61d_autoencoder.png)
Autoencoders in Deep Learning: Tutorial & Use Cases [2022]
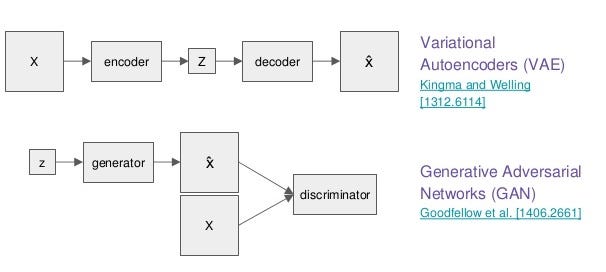
What a Disentangled Net We Weave: Representation Learning in ...

A deep adversarial variational autoencoder model for ...

VQ-VAE-2 Explained | Papers With Code

Variational AutoEncoders - GeeksforGeeks

LATENT SPACE REPRESENTATION: A HANDS-ON TUTORIAL ON ...

A deep-learning-based unsupervised model on esophageal ...

Deep learning for drug repurposing: Methods, databases, and ...
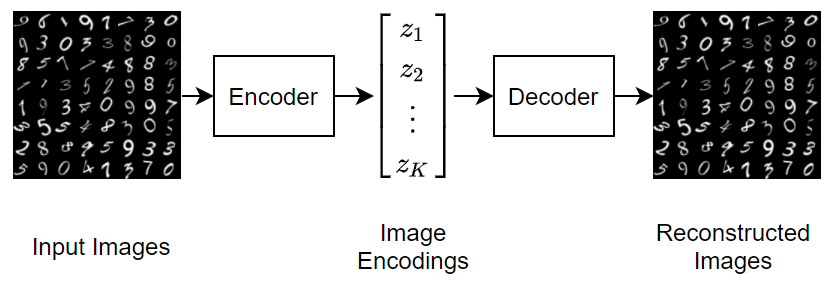
Train Variational Autoencoder (VAE) to Generate Images ...

Variational Autoencoder for Deep Learning of Images, Labels ...
![Autoencoders in Deep Learning: Tutorial & Use Cases [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/60e424b06f61a263edba1fe6_diagrammetic.png)
Autoencoders in Deep Learning: Tutorial & Use Cases [2022]
Variational Autoencoder Applications

Variational Autoencoder for Deep Learning of Images, Labels ...

A Tutorial on Variational Autoencoders with a Concise Keras ...
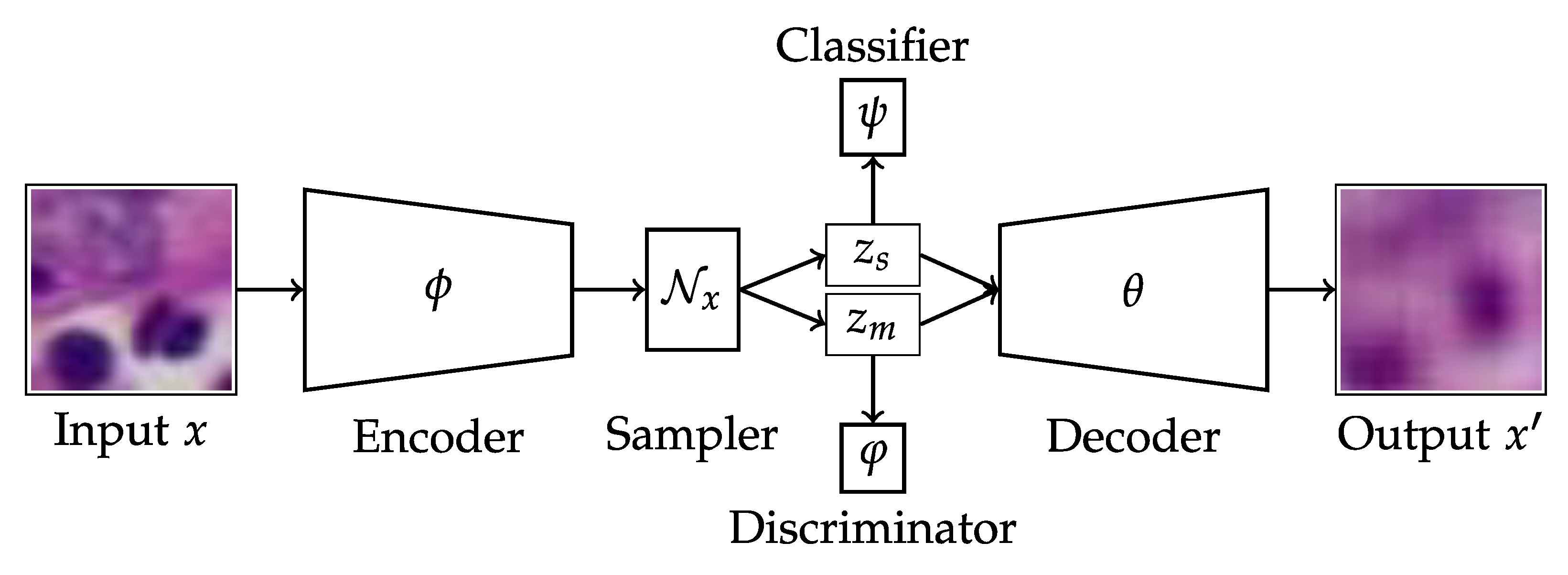
Applied Sciences | Free Full-Text | Disentangled Autoencoder ...
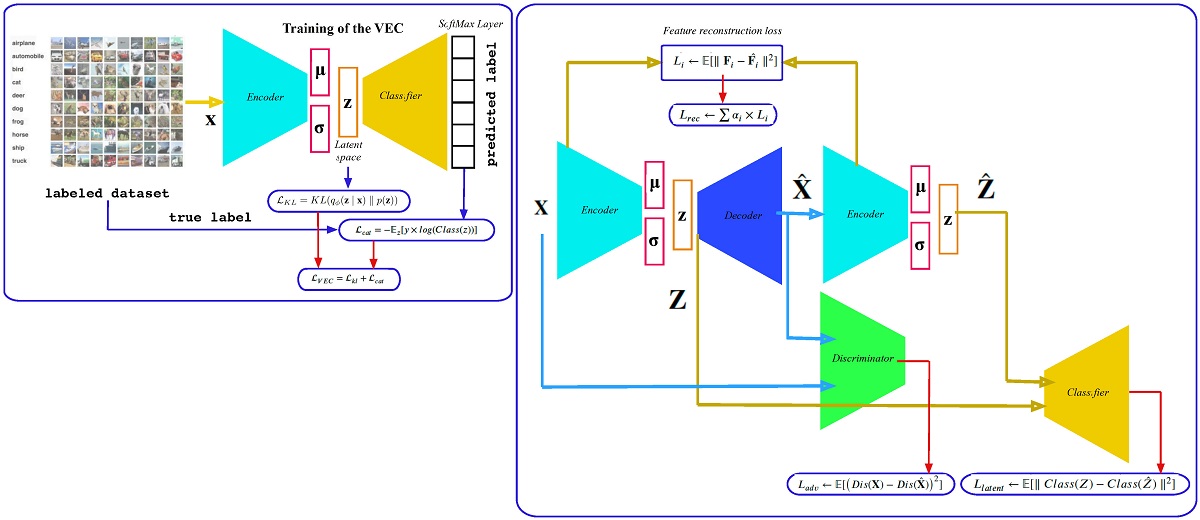
Semi-supervised Adversarial Variational Autoencoder[v1 ...

Convolutional variational autoencoder architecture. The deep ...

Train Variational Autoencoder (VAE) to Generate Images ...
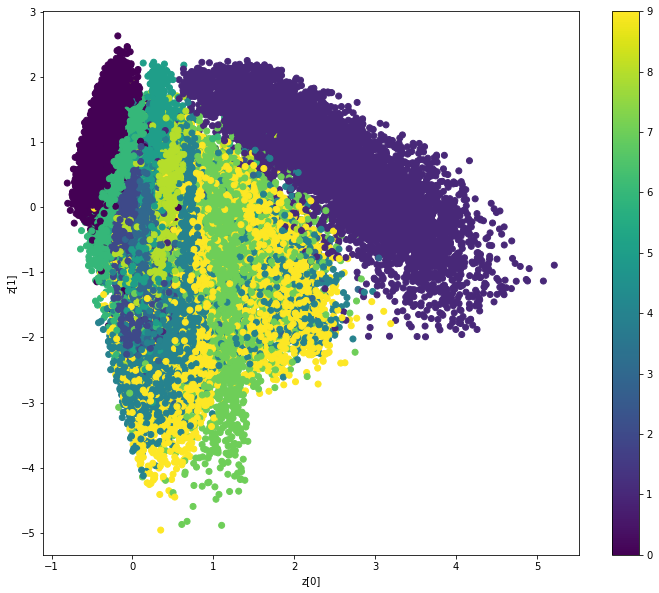
Variational AutoEncoder
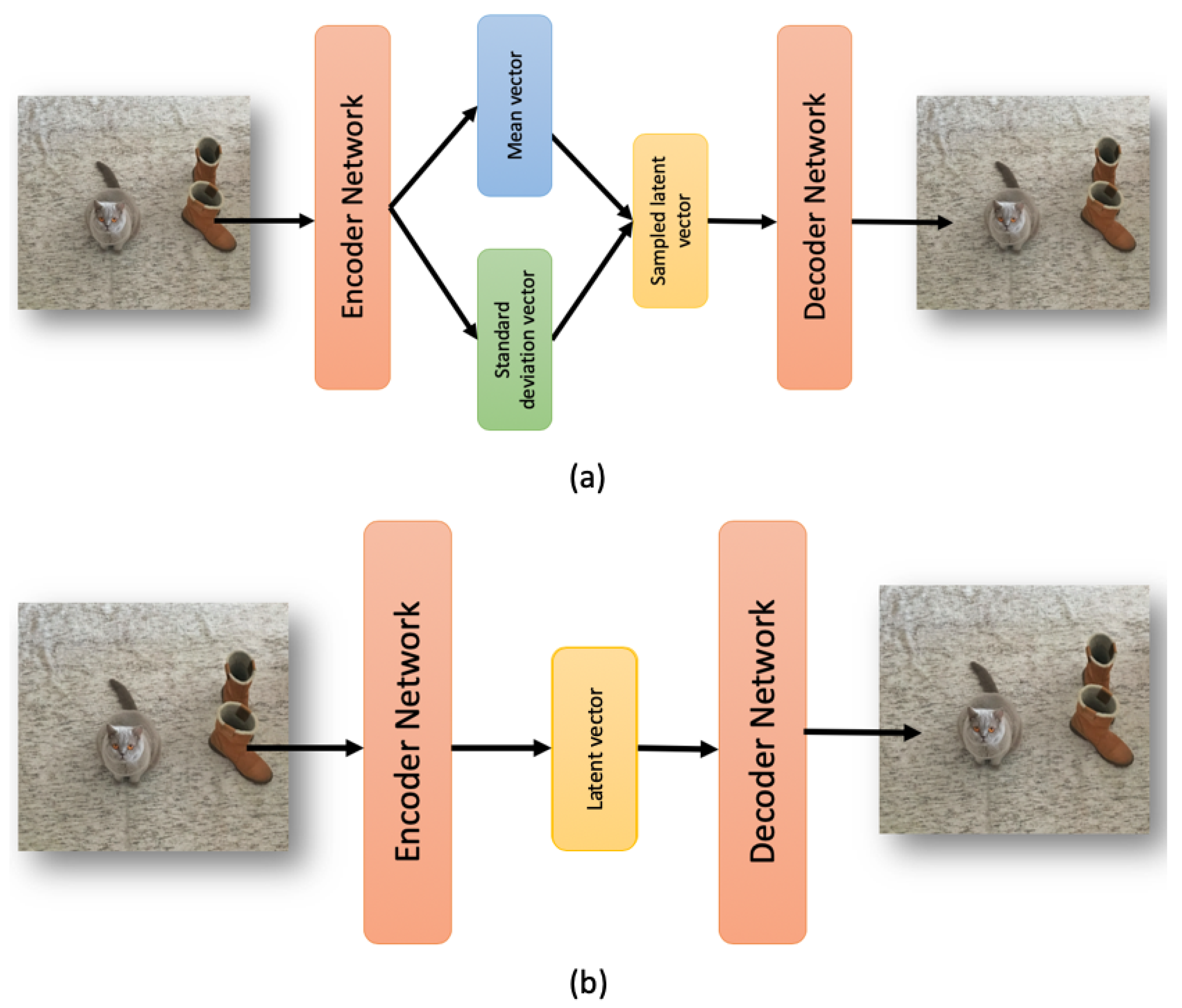
Sensors | Free Full-Text | Detecting Respiratory Pathologies ...

PDF) Variational Autoencoder for Deep Learning of Images ...
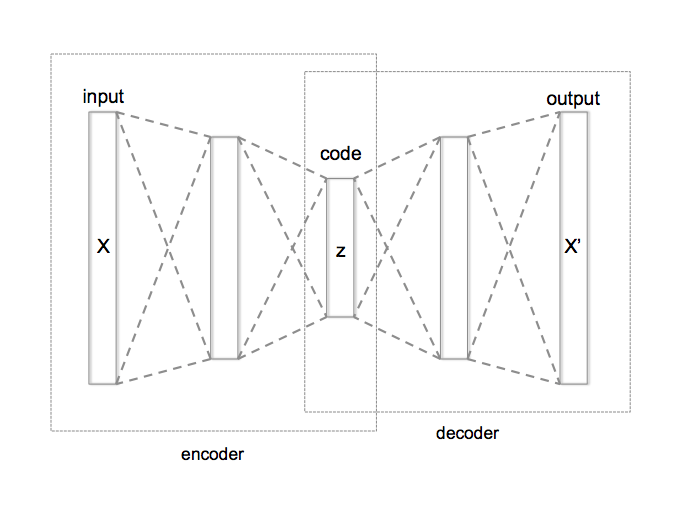
Implementing Autoencoders in Keras: Tutorial | DataCamp
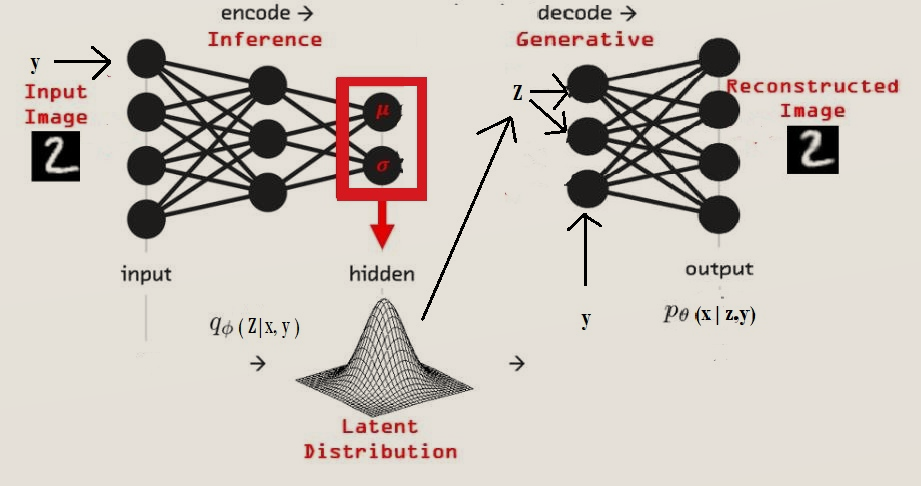
Understanding Conditional Variational Autoencoders | by Md ...

Use of Variational Autoencoders with Unsupervised Learning to ...
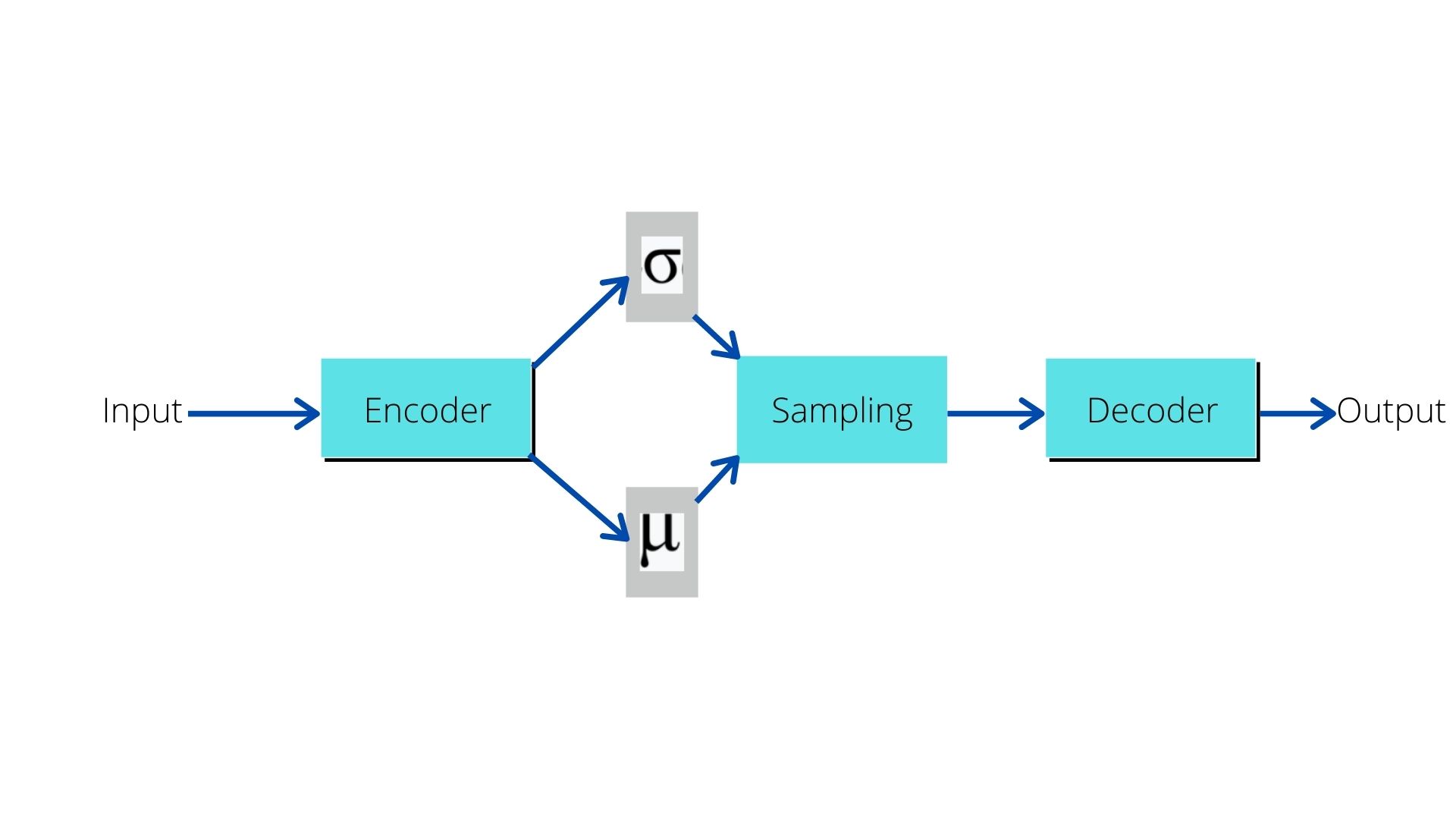
Convolutional Variational Autoencoder in PyTorch on MNIST ...

Guided Variational Autoencoder for Disentanglement Learning ...

Convolutional Variational Autoencoder in PyTorch on MNIST ...

Introduction to AutoEncoder and Variational AutoEncoder(VAE)
Gaussian Mixture Variational Autoencoder with Contrastive ...

a) Variational autoencoder (VAE) architecture for ...
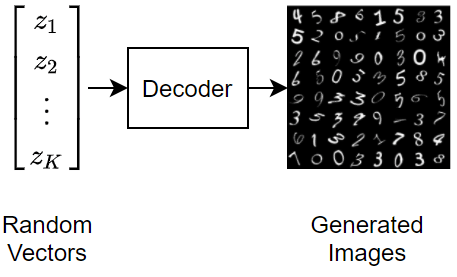
Train Variational Autoencoder (VAE) to Generate Images ...
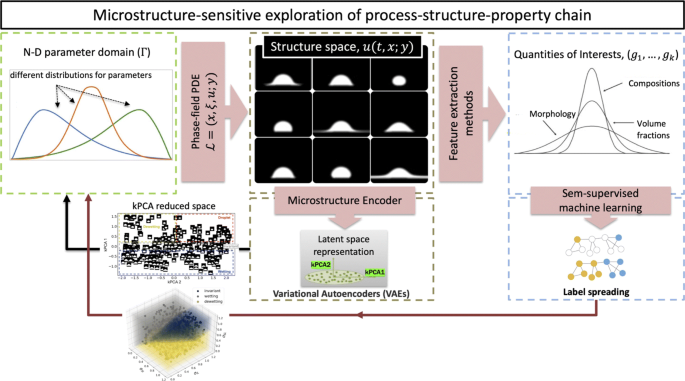
Machine learning-assisted high-throughput exploration of ...
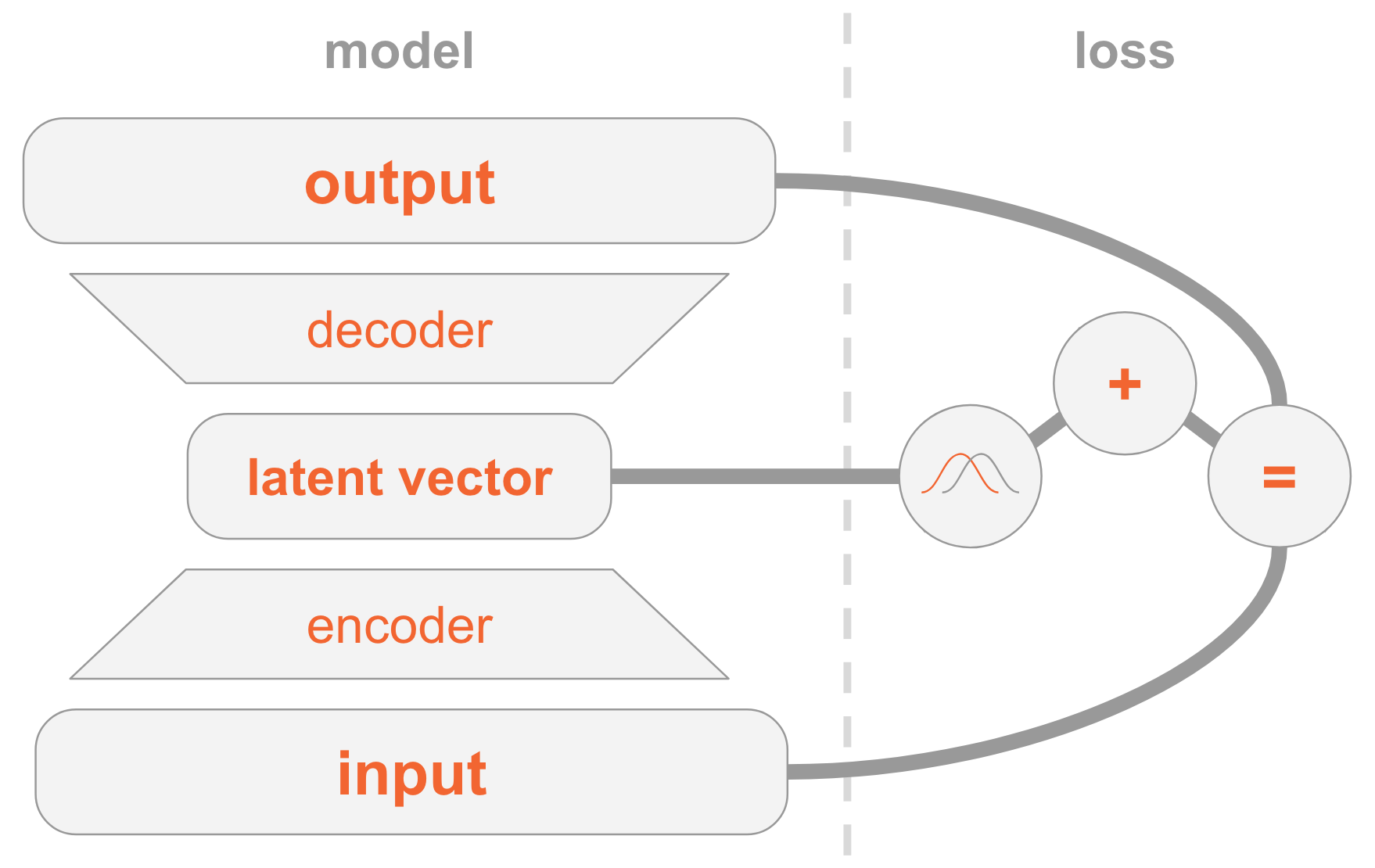
Variational Autoencoders Explained

Methods: (A) VAE/MMD-VAE architecture consists of an encoder ...

14. Variational Autoencoder — deep learning for molecules ...
Exploring Semi-supervised Variational Autoencoders for ...
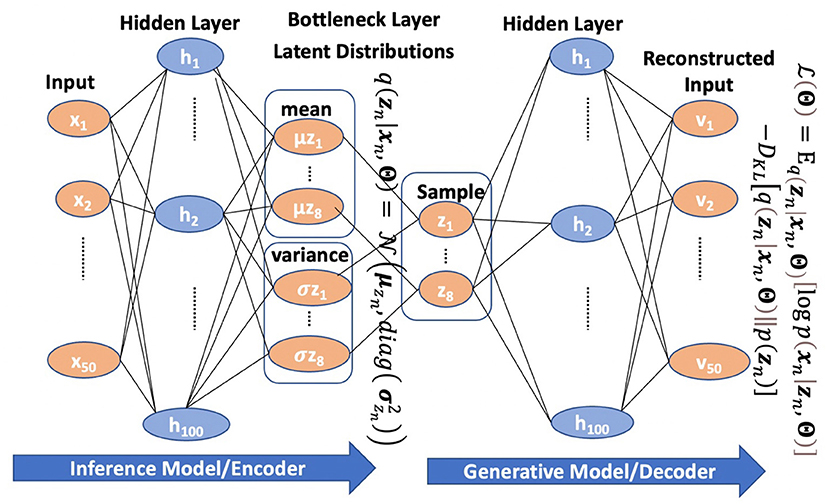
Frontiers | Exploring Factor Structures Using Variational ...

Variational autoencoder as a method of data augmentation ...
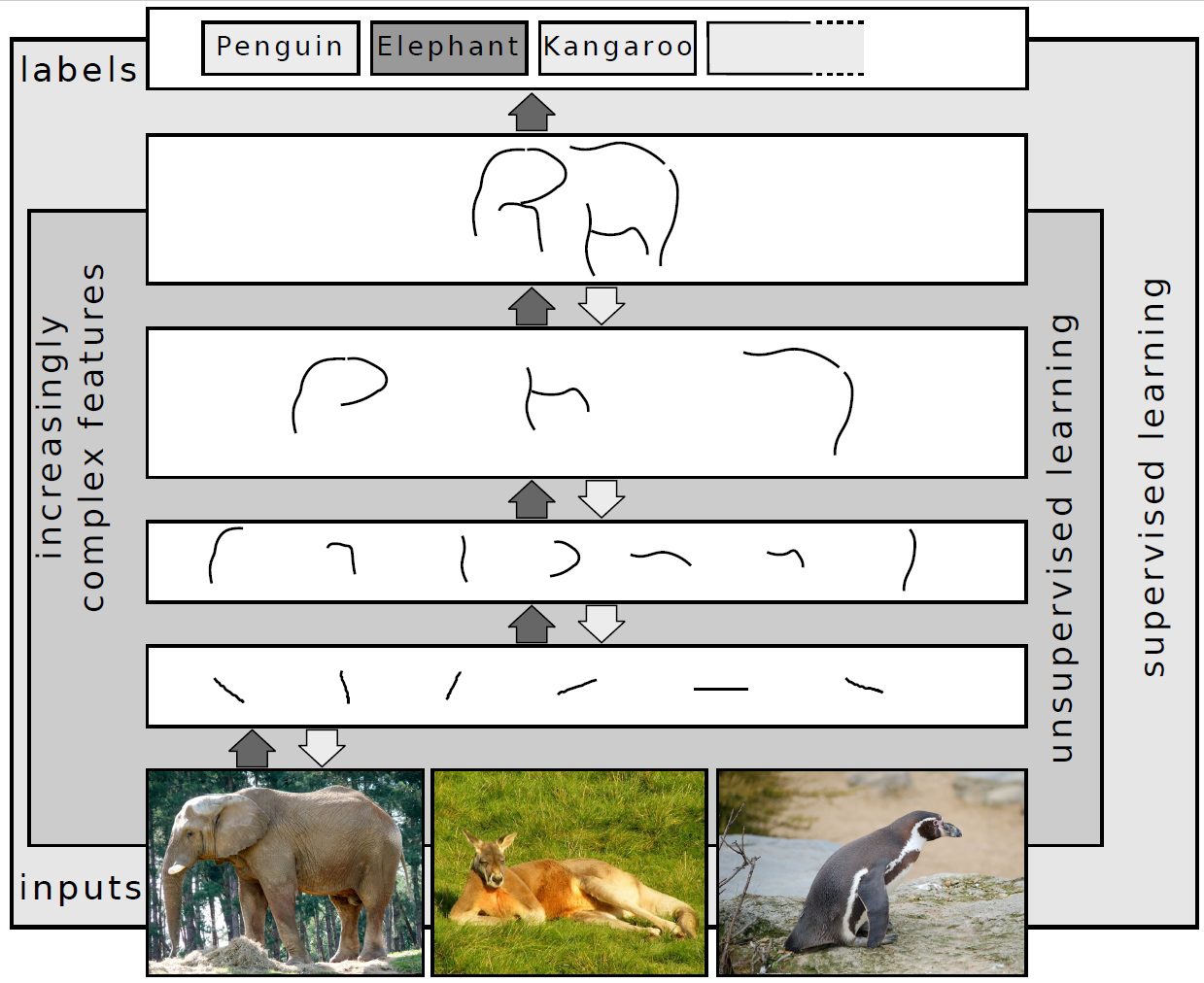
Deep learning - Wikipedia
Post a Comment for "43 variational autoencoder for deep learning of images labels and captions"